26
R有一个有用的函数pairs,它提供了数据集中变量之间成对连接图的很好矩阵。所得的情节看起来类似于下图,从this blog post复制:matplotlib类似的R````
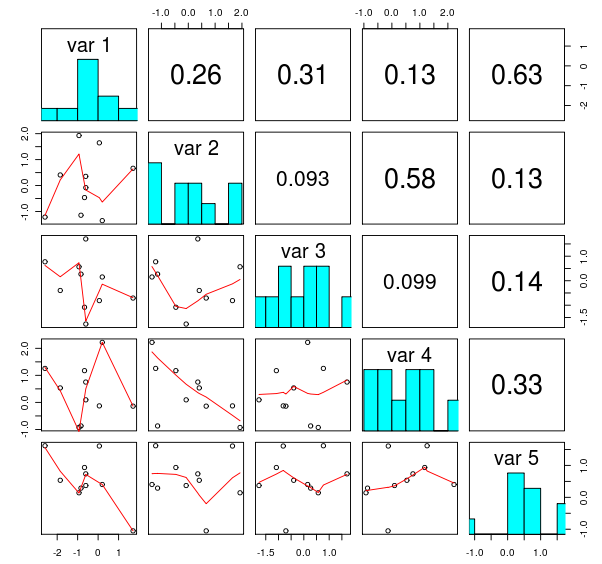
有没有准备基于Python的matplolib使用功能?我搜查了它的gallery,但找不到类似我需要的东西。从技术上讲,这应该是一项简单的任务,但对所有可能的案例,标签,标题等的适当处理是非常乏味的。
UPDATE请参阅下面我的答案,以快速和肮脏的近似值。

Seaborn有这个,请参阅:http://seaborn.pydata.org/generated/seaborn。 pairplot.html – 2017-09-14 19:04:37