我有一个基于GGPLOT2,热图呈现的某些因素的出现计数。但是,不同的数据集有时并不存在某些因素的实例,这意味着它们各自的热图看起来会有所不同。为了使并排比较更容易,我想添加缺少的级别。不幸的是我没有成功。添加缺少的因子水平的GGPLOT2热图
所以,我有一个看起来像这样的数据:
> head(numRules)
Job Generation NumRules
1 0 0 2
2 0 1 1
3 0 2 1
4 0 3 1
5 0 4 1
6 0 5 1
> levels(factor(numRules$NumRules))
[1] "1" "2" "3"
我使用下面的代码来渲染一个很好的热图计数每生成规则对所有岗位数量:
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules))) +
stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") +
ylab('Number of Rules')
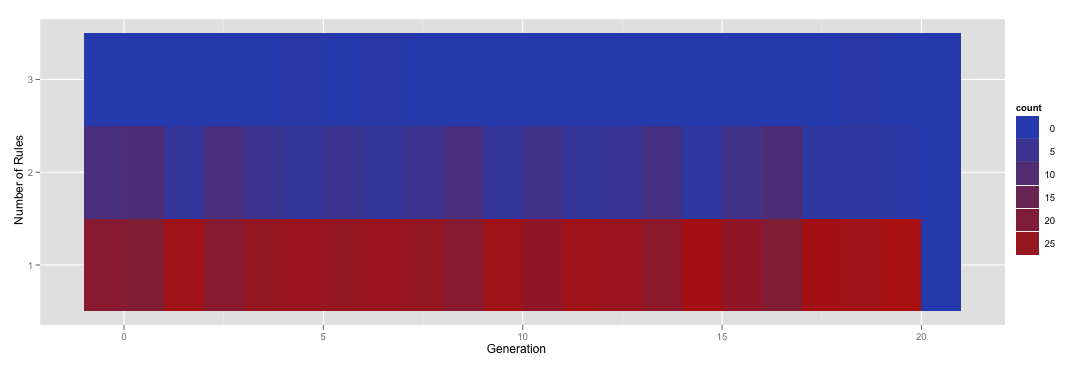
Heat map of count of number of rules by generation for all jobs
因此,热图说大多数时候运行只对特定的一代有一个单一的规则,但有时你会得到两个,并在极少数情况下你会得到三个离子。
现在完全不同的集运行的可能实际上有一个给定的一代零条规则。但是,进行并排比较会有点令人困惑,因为一张热图的y轴在[1,3]中有多个规则,而另一个可能在[0,2]中。我想要做的是标准化热点图表,以便他们所有都具有(0,1,2,3)中的因子级别,而不管规则的数量如何。例如,我想重新渲染上面的热图,即使在该特定数据框中没有该图的实例,也包括一个零规则的行。
我已经与包括设置休息和规模以及诸如此类的东西都没有用各种咒语[R殴打这一点。我的直觉是有一个简单的解决方案,但我无法找到它。
更新:
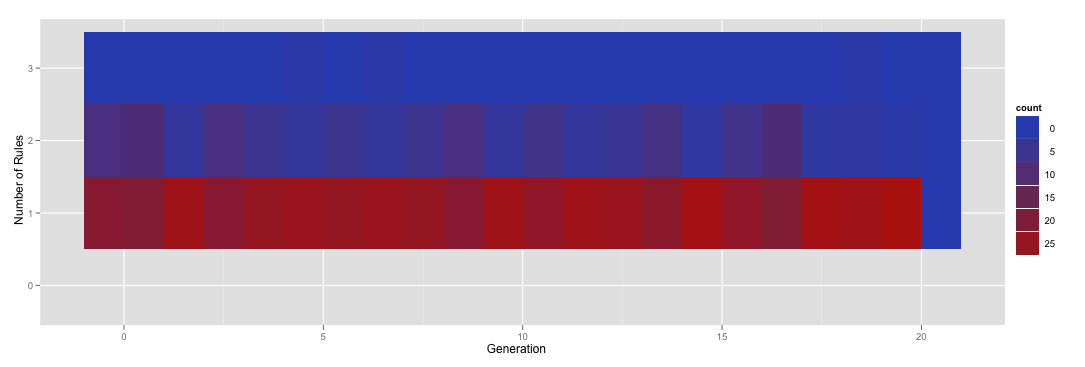
如果我手动指定呼叫的水平factor我得到增加了对零个规则中的一行:
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules,levels=c("0","1","2","3")))) + stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") + ylab('Number of Rules')
其中产量this。
不幸的是,你可以看到这个新行不正确着色。到达那里!


{kind=link}
{kind=link}
谢谢!这就是诀窍! – 2013-03-22 21:47:41