1
我有这样的文字:正则表达式匹配改进
<td class="devices-user-name">devicename</td>
<td>192.168.133.221</td>
<td>Storage Sync</td>
<td>10.3.3.335</td>
<td>Active</td>
<td>7/26/2016 8:39PM</td>
<td class="devices-details-button"><a class="btn btn-mini" href="#settings/devices/1/239a9cd0-d6c9-4e7d-9918-0cd686a57aac">Details</a></td>
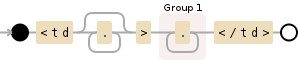
我想赶上<td> </td>以及之间的一切<td class=...> </td>
我实现的是这个表达式:
<td.*>(.*?)<\/td>(\n(.*<td>(.*?)<\/td>))(\n(.*<td>(.*?)<\/td>))(\n(.*<td>(.*?)<\/td>))(\n(.*<td>(.*?)<\/td>))(\n(.*<td>(.*?)<\/td>))(\n(.*<td.*href="(.*?)"))
之后我仍然需要排除所有匹配的<td>:
$MatchResult = $Matches.GetEnumerator() | ? {$_.Value -notmatch 'td'} | Sort Name
最后我得到这个结果:
Name Value
---- -----
1 devicename
4 192.168.133.221
7 Storage Sync
10 10.3.3.335
13 Active
16 7/26/2016 8:39PM
19 #settings/devices/1/239a9cd0-d6c9-4e7d-9918-0cd686a57aac
但我安静确保有一个更好的办法,而不是重复的组,但不包括的东西等使用一些其他/更好的工艺,这是我”我很乐意学习。
你的建议是什么?
请访问http://计算器.com/a/11656434/3832970的替代方法。 –
关于用RegEx解析HTML,[请先阅读本文](http://stackoverflow.com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags/1732454#1732454) –