说明
(?<="personEmail":")[^"]+(?=")
**要看到图像更好,只需右键点击在新窗口中的图像,然后选择查看
这个正则表达式将执行以下操作:
- 找到val UE相关联的
personEmail字段
例
现场演示
https://regex101.com/r/aH1nO9/2
示例文本
GFyazovL3VzL1BFT1BMRS9mNWQzMGMyYi1mZDMyLTRhYT ytYjZhYS1iYTdkYWNjZWZiN2M“,”personEmail“:”[email protected]“,”created“:”2016-07-13T19:19:14.934Z“,”html“:”blah-data-object-type = \“person \ “数据OBJECTID = \” [email protected]M4LTQzNDAtOWE2ZC0xMmRmYzI5YWU5
样品匹配
MATCH 1
0. [87-105] `[email protected]vider.com`
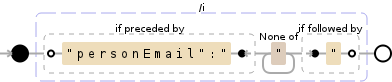
说明
NODE EXPLANATION
--------------------------------------------------------------------------------
(?<= look behind to see if there is:
--------------------------------------------------------------------------------
"personEmail":" '"personEmail":"'
--------------------------------------------------------------------------------
) end of look-behind
--------------------------------------------------------------------------------
[^"]+ any character except: '"' (1 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
(?= look ahead to see if there is:
--------------------------------------------------------------------------------
" '"'
--------------------------------------------------------------------------------
) end of look-ahead
根据您的示例文本,你可以用这个正则表达式匹配的邮件:'perso nEmail“:”(\ w + @(?:\ w + \。)+ \ w +)“'(您可以根据需要改进电子邮件正则表达式,这里有很多示例)。 – Alfeu